Flu Syndrome (SG)
Description
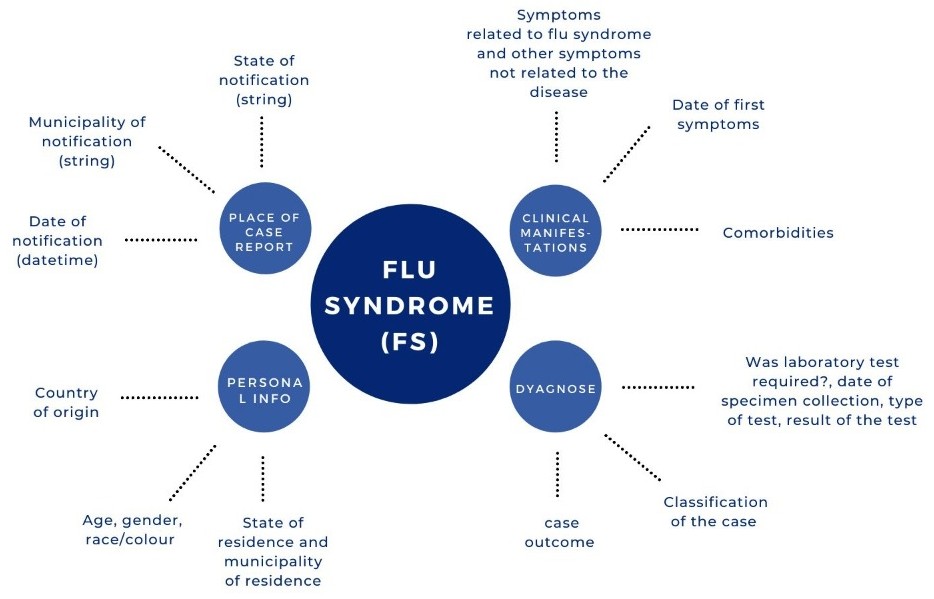
With the emergence of the pandemic caused by SARS-COV-2, the Brazilian Ministry of Health implemented a surveillance system to record Flu Syndrome (FS) (the e-SUS VE) of mild to moderate cases suspected of COVID-19. The data is built by the private and public health care units, which report the suspected cases to the e-SUS NOTIFICA system.
A suspected case of flu syndrome is a patient presenting at least two of the following clinical conditions: fever (even if referred), chills, sore throat, headache, cough, runny nose, olfactory disorders or taste disorders. For children, nasal obstruction is one more condition considered. While for older people, syncope, mental confusion, excessive sleepiness, irritability and inappetence represent an aggravation of the case. To clinically assign the case as a SARS-COV-2 infection, in addition to the characteristics listed before, patients may be followed by anosmia, ageusia, diarrhoea, abdominal pain, myalgia, fatigue (Ministério da Saúde, 2020).
The data includes information referring to the patient's place of residence (fields: state, municipality), regardless of whether they have been notified in another state or municipality (Fields: Notification state, Notification municipality), in addition to demographic and clinical epidemiological issues, (Ministério da Saúde, 2020), (Observatório COVID-19, 2020).
Links to publications that use the SG data or provide other publicly accessible locations of the data can be found in (Observatório COVID-19, 2020).
Data access information
The SG data is licensed under a Creative Commons Attribution License cc-by (version 4.0), see (Ministério da Saúde, 2020a). Additionally, the SG dataset is publicly available and published by the Ministry of Health of Brazil.
Therefore, no approval by an ethics committee is required to use this data, according to Resolutions 466/2012 and 510/2016 (article 1, sections III and V) from the National Health Council (CNS), Brazil.
Methods of data collection
A python code is available on our Github directory to download the SG data from the OpenDatasus , see details in Github. We are pulling the SG data from 2019 and on. The database is updated weekly in our project, being a version associated with its date of update.
Data-specific information for SG
The SG dataset has a total of 30 columns and showed a total of 48,288,827 registries (rows) and a size of 14 GB in the last update of August 19th, 2021. A code with more details about the variables, data processing and analysis methods is presented in our Github directory.
Limitations of SG dataset
Several cases in the SG dataset lack final classification. Every case in SG will have a final classification given by the epidemiological surveillance teams of the Secretariat of Health. However, given the number of registered patients, they may not be classified on time (some even closed and not analysed anymore).
To overcome such a difficulty, our team will apply a classification algorithm to give a pre-diagnosis of the cases in SG that have no final classification. The algorithm is applied to the information of symptoms that is available in the dataset.
Schematic view of the SG database